A statement that could be true, which might then be tested.
Example: Sam has a hypothesis that "large dogs are better at catching tennis balls than small dogs". We can test that hypothesis by having hundreds of different sized dogs try to catch tennis balls.
Sometimes the hypothesis won't be tested, it is simply a good explanation (which could be wrong). Conjecture is a better word for this.
Example: you notice the temperature drops just as the sun rises. Your hypothesis is that the sun warms the air high above you, which rises up and then cooler air comes from the sides.
Note: when someone says "I have a theory" they should say "I have a hypothesis", because in mathematics a theory is actually well proven.

Hypothesis Testing
Hypothesis testing is a tool for making statistical inferences about the population data. It is an analysis tool that tests assumptions and determines how likely something is within a given standard of accuracy. Hypothesis testing provides a way to verify whether the results of an experiment are valid.
A null hypothesis and an alternative hypothesis are set up before performing the hypothesis testing. This helps to arrive at a conclusion regarding the sample obtained from the population. In this article, we will learn more about hypothesis testing, its types, steps to perform the testing, and associated examples.
| 1. | |
| 2. | |
| 3. | |
| 4. | |
| 5. | |
| 6. | |
| 7. | |
| 8. |
What is Hypothesis Testing in Statistics?
Hypothesis testing uses sample data from the population to draw useful conclusions regarding the population probability distribution . It tests an assumption made about the data using different types of hypothesis testing methodologies. The hypothesis testing results in either rejecting or not rejecting the null hypothesis.
Hypothesis Testing Definition
Hypothesis testing can be defined as a statistical tool that is used to identify if the results of an experiment are meaningful or not. It involves setting up a null hypothesis and an alternative hypothesis. These two hypotheses will always be mutually exclusive. This means that if the null hypothesis is true then the alternative hypothesis is false and vice versa. An example of hypothesis testing is setting up a test to check if a new medicine works on a disease in a more efficient manner.
Null Hypothesis
The null hypothesis is a concise mathematical statement that is used to indicate that there is no difference between two possibilities. In other words, there is no difference between certain characteristics of data. This hypothesis assumes that the outcomes of an experiment are based on chance alone. It is denoted as \(H_{0}\). Hypothesis testing is used to conclude if the null hypothesis can be rejected or not. Suppose an experiment is conducted to check if girls are shorter than boys at the age of 5. The null hypothesis will say that they are the same height.
Alternative Hypothesis
The alternative hypothesis is an alternative to the null hypothesis. It is used to show that the observations of an experiment are due to some real effect. It indicates that there is a statistical significance between two possible outcomes and can be denoted as \(H_{1}\) or \(H_{a}\). For the above-mentioned example, the alternative hypothesis would be that girls are shorter than boys at the age of 5.
Hypothesis Testing P Value
In hypothesis testing, the p value is used to indicate whether the results obtained after conducting a test are statistically significant or not. It also indicates the probability of making an error in rejecting or not rejecting the null hypothesis.This value is always a number between 0 and 1. The p value is compared to an alpha level, \(\alpha\) or significance level. The alpha level can be defined as the acceptable risk of incorrectly rejecting the null hypothesis. The alpha level is usually chosen between 1% to 5%.
Hypothesis Testing Critical region
All sets of values that lead to rejecting the null hypothesis lie in the critical region. Furthermore, the value that separates the critical region from the non-critical region is known as the critical value.
Hypothesis Testing Formula
Depending upon the type of data available and the size, different types of hypothesis testing are used to determine whether the null hypothesis can be rejected or not. The hypothesis testing formula for some important test statistics are given below:
- z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\). \(\overline{x}\) is the sample mean, \(\mu\) is the population mean, \(\sigma\) is the population standard deviation and n is the size of the sample.
- t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\). s is the sample standard deviation.
- \(\chi ^{2} = \sum \frac{(O_{i}-E_{i})^{2}}{E_{i}}\). \(O_{i}\) is the observed value and \(E_{i}\) is the expected value.
We will learn more about these test statistics in the upcoming section.
Types of Hypothesis Testing
Selecting the correct test for performing hypothesis testing can be confusing. These tests are used to determine a test statistic on the basis of which the null hypothesis can either be rejected or not rejected. Some of the important tests used for hypothesis testing are given below.
Hypothesis Testing Z Test
A z test is a way of hypothesis testing that is used for a large sample size (n ≥ 30). It is used to determine whether there is a difference between the population mean and the sample mean when the population standard deviation is known. It can also be used to compare the mean of two samples. It is used to compute the z test statistic. The formulas are given as follows:
- One sample: z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\).
- Two samples: z = \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{\sigma_{1}^{2}}{n_{1}}+\frac{\sigma_{2}^{2}}{n_{2}}}}\).
Hypothesis Testing t Test
The t test is another method of hypothesis testing that is used for a small sample size (n < 30). It is also used to compare the sample mean and population mean. However, the population standard deviation is not known. Instead, the sample standard deviation is known. The mean of two samples can also be compared using the t test.
- One sample: t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\).
- Two samples: t = \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{s_{1}^{2}}{n_{1}}+\frac{s_{2}^{2}}{n_{2}}}}\).
Hypothesis Testing Chi Square
The Chi square test is a hypothesis testing method that is used to check whether the variables in a population are independent or not. It is used when the test statistic is chi-squared distributed.
One Tailed Hypothesis Testing
One tailed hypothesis testing is done when the rejection region is only in one direction. It can also be known as directional hypothesis testing because the effects can be tested in one direction only. This type of testing is further classified into the right tailed test and left tailed test.
Right Tailed Hypothesis Testing
The right tail test is also known as the upper tail test. This test is used to check whether the population parameter is greater than some value. The null and alternative hypotheses for this test are given as follows:
\(H_{0}\): The population parameter is ≤ some value
\(H_{1}\): The population parameter is > some value.
If the test statistic has a greater value than the critical value then the null hypothesis is rejected

Left Tailed Hypothesis Testing
The left tail test is also known as the lower tail test. It is used to check whether the population parameter is less than some value. The hypotheses for this hypothesis testing can be written as follows:
\(H_{0}\): The population parameter is ≥ some value
\(H_{1}\): The population parameter is < some value.
The null hypothesis is rejected if the test statistic has a value lesser than the critical value.

Two Tailed Hypothesis Testing
In this hypothesis testing method, the critical region lies on both sides of the sampling distribution. It is also known as a non - directional hypothesis testing method. The two-tailed test is used when it needs to be determined if the population parameter is assumed to be different than some value. The hypotheses can be set up as follows:
\(H_{0}\): the population parameter = some value
\(H_{1}\): the population parameter ≠ some value
The null hypothesis is rejected if the test statistic has a value that is not equal to the critical value.

Hypothesis Testing Steps
Hypothesis testing can be easily performed in five simple steps. The most important step is to correctly set up the hypotheses and identify the right method for hypothesis testing. The basic steps to perform hypothesis testing are as follows:
- Step 1: Set up the null hypothesis by correctly identifying whether it is the left-tailed, right-tailed, or two-tailed hypothesis testing.
- Step 2: Set up the alternative hypothesis.
- Step 3: Choose the correct significance level, \(\alpha\), and find the critical value.
- Step 4: Calculate the correct test statistic (z, t or \(\chi\)) and p-value.
- Step 5: Compare the test statistic with the critical value or compare the p-value with \(\alpha\) to arrive at a conclusion. In other words, decide if the null hypothesis is to be rejected or not.
Hypothesis Testing Example
The best way to solve a problem on hypothesis testing is by applying the 5 steps mentioned in the previous section. Suppose a researcher claims that the mean average weight of men is greater than 100kgs with a standard deviation of 15kgs. 30 men are chosen with an average weight of 112.5 Kgs. Using hypothesis testing, check if there is enough evidence to support the researcher's claim. The confidence interval is given as 95%.
Step 1: This is an example of a right-tailed test. Set up the null hypothesis as \(H_{0}\): \(\mu\) = 100.
Step 2: The alternative hypothesis is given by \(H_{1}\): \(\mu\) > 100.
Step 3: As this is a one-tailed test, \(\alpha\) = 100% - 95% = 5%. This can be used to determine the critical value.
1 - \(\alpha\) = 1 - 0.05 = 0.95
0.95 gives the required area under the curve. Now using a normal distribution table, the area 0.95 is at z = 1.645. A similar process can be followed for a t-test. The only additional requirement is to calculate the degrees of freedom given by n - 1.
Step 4: Calculate the z test statistic. This is because the sample size is 30. Furthermore, the sample and population means are known along with the standard deviation.
z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\).
\(\mu\) = 100, \(\overline{x}\) = 112.5, n = 30, \(\sigma\) = 15
z = \(\frac{112.5-100}{\frac{15}{\sqrt{30}}}\) = 4.56
Step 5: Conclusion. As 4.56 > 1.645 thus, the null hypothesis can be rejected.
Hypothesis Testing and Confidence Intervals
Confidence intervals form an important part of hypothesis testing. This is because the alpha level can be determined from a given confidence interval. Suppose a confidence interval is given as 95%. Subtract the confidence interval from 100%. This gives 100 - 95 = 5% or 0.05. This is the alpha value of a one-tailed hypothesis testing. To obtain the alpha value for a two-tailed hypothesis testing, divide this value by 2. This gives 0.05 / 2 = 0.025.
Related Articles:
- Probability and Statistics
- Data Handling
Important Notes on Hypothesis Testing
- Hypothesis testing is a technique that is used to verify whether the results of an experiment are statistically significant.
- It involves the setting up of a null hypothesis and an alternate hypothesis.
- There are three types of tests that can be conducted under hypothesis testing - z test, t test, and chi square test.
- Hypothesis testing can be classified as right tail, left tail, and two tail tests.
Examples on Hypothesis Testing
- Example 1: The average weight of a dumbbell in a gym is 90lbs. However, a physical trainer believes that the average weight might be higher. A random sample of 5 dumbbells with an average weight of 110lbs and a standard deviation of 18lbs. Using hypothesis testing check if the physical trainer's claim can be supported for a 95% confidence level. Solution: As the sample size is lesser than 30, the t-test is used. \(H_{0}\): \(\mu\) = 90, \(H_{1}\): \(\mu\) > 90 \(\overline{x}\) = 110, \(\mu\) = 90, n = 5, s = 18. \(\alpha\) = 0.05 Using the t-distribution table, the critical value is 2.132 t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\) t = 2.484 As 2.484 > 2.132, the null hypothesis is rejected. Answer: The average weight of the dumbbells may be greater than 90lbs
- Example 2: The average score on a test is 80 with a standard deviation of 10. With a new teaching curriculum introduced it is believed that this score will change. On random testing, the score of 38 students, the mean was found to be 88. With a 0.05 significance level, is there any evidence to support this claim? Solution: This is an example of two-tail hypothesis testing. The z test will be used. \(H_{0}\): \(\mu\) = 80, \(H_{1}\): \(\mu\) ≠ 80 \(\overline{x}\) = 88, \(\mu\) = 80, n = 36, \(\sigma\) = 10. \(\alpha\) = 0.05 / 2 = 0.025 The critical value using the normal distribution table is 1.96 z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\) z = \(\frac{88-80}{\frac{10}{\sqrt{36}}}\) = 4.8 As 4.8 > 1.96, the null hypothesis is rejected. Answer: There is a difference in the scores after the new curriculum was introduced.
- Example 3: The average score of a class is 90. However, a teacher believes that the average score might be lower. The scores of 6 students were randomly measured. The mean was 82 with a standard deviation of 18. With a 0.05 significance level use hypothesis testing to check if this claim is true. Solution: The t test will be used. \(H_{0}\): \(\mu\) = 90, \(H_{1}\): \(\mu\) < 90 \(\overline{x}\) = 110, \(\mu\) = 90, n = 6, s = 18 The critical value from the t table is -2.015 t = \(\frac{\overline{x}-\mu}{\frac{s}{\sqrt{n}}}\) t = \(\frac{82-90}{\frac{18}{\sqrt{6}}}\) t = -1.088 As -1.088 > -2.015, we fail to reject the null hypothesis. Answer: There is not enough evidence to support the claim.
go to slide go to slide go to slide

Book a Free Trial Class
FAQs on Hypothesis Testing
What is hypothesis testing.
Hypothesis testing in statistics is a tool that is used to make inferences about the population data. It is also used to check if the results of an experiment are valid.
What is the z Test in Hypothesis Testing?
The z test in hypothesis testing is used to find the z test statistic for normally distributed data . The z test is used when the standard deviation of the population is known and the sample size is greater than or equal to 30.
What is the t Test in Hypothesis Testing?
The t test in hypothesis testing is used when the data follows a student t distribution . It is used when the sample size is less than 30 and standard deviation of the population is not known.
What is the formula for z test in Hypothesis Testing?
The formula for a one sample z test in hypothesis testing is z = \(\frac{\overline{x}-\mu}{\frac{\sigma}{\sqrt{n}}}\) and for two samples is z = \(\frac{(\overline{x_{1}}-\overline{x_{2}})-(\mu_{1}-\mu_{2})}{\sqrt{\frac{\sigma_{1}^{2}}{n_{1}}+\frac{\sigma_{2}^{2}}{n_{2}}}}\).
What is the p Value in Hypothesis Testing?
The p value helps to determine if the test results are statistically significant or not. In hypothesis testing, the null hypothesis can either be rejected or not rejected based on the comparison between the p value and the alpha level.
What is One Tail Hypothesis Testing?
When the rejection region is only on one side of the distribution curve then it is known as one tail hypothesis testing. The right tail test and the left tail test are two types of directional hypothesis testing.
What is the Alpha Level in Two Tail Hypothesis Testing?
To get the alpha level in a two tail hypothesis testing divide \(\alpha\) by 2. This is done as there are two rejection regions in the curve.
Reset password New user? Sign up
Existing user? Log in
Hypothesis Testing
Already have an account? Log in here.
A hypothesis test is a statistical inference method used to test the significance of a proposed (hypothesized) relation between population statistics (parameters) and their corresponding sample estimators . In other words, hypothesis tests are used to determine if there is enough evidence in a sample to prove a hypothesis true for the entire population.
The test considers two hypotheses: the null hypothesis , which is a statement meant to be tested, usually something like "there is no effect" with the intention of proving this false, and the alternate hypothesis , which is the statement meant to stand after the test is performed. The two hypotheses must be mutually exclusive ; moreover, in most applications, the two are complementary (one being the negation of the other). The test works by comparing the \(p\)-value to the level of significance (a chosen target). If the \(p\)-value is less than or equal to the level of significance, then the null hypothesis is rejected.
When analyzing data, only samples of a certain size might be manageable as efficient computations. In some situations the error terms follow a continuous or infinite distribution, hence the use of samples to suggest accuracy of the chosen test statistics. The method of hypothesis testing gives an advantage over guessing what distribution or which parameters the data follows.
Definitions and Methodology
Hypothesis test and confidence intervals.
In statistical inference, properties (parameters) of a population are analyzed by sampling data sets. Given assumptions on the distribution, i.e. a statistical model of the data, certain hypotheses can be deduced from the known behavior of the model. These hypotheses must be tested against sampled data from the population.
The null hypothesis \((\)denoted \(H_0)\) is a statement that is assumed to be true. If the null hypothesis is rejected, then there is enough evidence (statistical significance) to accept the alternate hypothesis \((\)denoted \(H_1).\) Before doing any test for significance, both hypotheses must be clearly stated and non-conflictive, i.e. mutually exclusive, statements. Rejecting the null hypothesis, given that it is true, is called a type I error and it is denoted \(\alpha\), which is also its probability of occurrence. Failing to reject the null hypothesis, given that it is false, is called a type II error and it is denoted \(\beta\), which is also its probability of occurrence. Also, \(\alpha\) is known as the significance level , and \(1-\beta\) is known as the power of the test. \(H_0\) \(\textbf{is true}\)\(\hspace{15mm}\) \(H_0\) \(\textbf{is false}\) \(\textbf{Reject}\) \(H_0\)\(\hspace{10mm}\) Type I error Correct Decision \(\textbf{Reject}\) \(H_1\) Correct Decision Type II error The test statistic is the standardized value following the sampled data under the assumption that the null hypothesis is true, and a chosen particular test. These tests depend on the statistic to be studied and the assumed distribution it follows, e.g. the population mean following a normal distribution. The \(p\)-value is the probability of observing an extreme test statistic in the direction of the alternate hypothesis, given that the null hypothesis is true. The critical value is the value of the assumed distribution of the test statistic such that the probability of making a type I error is small.
Methodologies: Given an estimator \(\hat \theta\) of a population statistic \(\theta\), following a probability distribution \(P(T)\), computed from a sample \(\mathcal{S},\) and given a significance level \(\alpha\) and test statistic \(t^*,\) define \(H_0\) and \(H_1;\) compute the test statistic \(t^*.\) \(p\)-value Approach (most prevalent): Find the \(p\)-value using \(t^*\) (right-tailed). If the \(p\)-value is at most \(\alpha,\) reject \(H_0\). Otherwise, reject \(H_1\). Critical Value Approach: Find the critical value solving the equation \(P(T\geq t_\alpha)=\alpha\) (right-tailed). If \(t^*>t_\alpha\), reject \(H_0\). Otherwise, reject \(H_1\). Note: Failing to reject \(H_0\) only means inability to accept \(H_1\), and it does not mean to accept \(H_0\).
Assume a normally distributed population has recorded cholesterol levels with various statistics computed. From a sample of 100 subjects in the population, the sample mean was 214.12 mg/dL (milligrams per deciliter), with a sample standard deviation of 45.71 mg/dL. Perform a hypothesis test, with significance level 0.05, to test if there is enough evidence to conclude that the population mean is larger than 200 mg/dL. Hypothesis Test We will perform a hypothesis test using the \(p\)-value approach with significance level \(\alpha=0.05:\) Define \(H_0\): \(\mu=200\). Define \(H_1\): \(\mu>200\). Since our values are normally distributed, the test statistic is \(z^*=\frac{\bar X - \mu_0}{\frac{s}{\sqrt{n}}}=\frac{214.12 - 200}{\frac{45.71}{\sqrt{100}}}\approx 3.09\). Using a standard normal distribution, we find that our \(p\)-value is approximately \(0.001\). Since the \(p\)-value is at most \(\alpha=0.05,\) we reject \(H_0\). Therefore, we can conclude that the test shows sufficient evidence to support the claim that \(\mu\) is larger than \(200\) mg/dL.
If the sample size was smaller, the normal and \(t\)-distributions behave differently. Also, the question itself must be managed by a double-tail test instead.
Assume a population's cholesterol levels are recorded and various statistics are computed. From a sample of 25 subjects, the sample mean was 214.12 mg/dL (milligrams per deciliter), with a sample standard deviation of 45.71 mg/dL. Perform a hypothesis test, with significance level 0.05, to test if there is enough evidence to conclude that the population mean is not equal to 200 mg/dL. Hypothesis Test We will perform a hypothesis test using the \(p\)-value approach with significance level \(\alpha=0.05\) and the \(t\)-distribution with 24 degrees of freedom: Define \(H_0\): \(\mu=200\). Define \(H_1\): \(\mu\neq 200\). Using the \(t\)-distribution, the test statistic is \(t^*=\frac{\bar X - \mu_0}{\frac{s}{\sqrt{n}}}=\frac{214.12 - 200}{\frac{45.71}{\sqrt{25}}}\approx 1.54\). Using a \(t\)-distribution with 24 degrees of freedom, we find that our \(p\)-value is approximately \(2(0.068)=0.136\). We have multiplied by two since this is a two-tailed argument, i.e. the mean can be smaller than or larger than. Since the \(p\)-value is larger than \(\alpha=0.05,\) we fail to reject \(H_0\). Therefore, the test does not show sufficient evidence to support the claim that \(\mu\) is not equal to \(200\) mg/dL.
The complement of the rejection on a two-tailed hypothesis test (with significance level \(\alpha\)) for a population parameter \(\theta\) is equivalent to finding a confidence interval \((\)with confidence level \(1-\alpha)\) for the population parameter \(\theta\). If the assumption on the parameter \(\theta\) falls inside the confidence interval, then the test has failed to reject the null hypothesis \((\)with \(p\)-value greater than \(\alpha).\) Otherwise, if \(\theta\) does not fall in the confidence interval, then the null hypothesis is rejected in favor of the alternate \((\)with \(p\)-value at most \(\alpha).\)
- Statistics (Estimation)
- Normal Distribution
- Correlation
- Confidence Intervals
Problem Loading...
Note Loading...
Set Loading...
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
17 Introduction to Hypothesis Testing
Jenna Lehmann
What is Hypothesis Testing?
Hypothesis testing is a big part of what we would actually consider testing for inferential statistics. It’s a procedure and set of rules that allow us to move from descriptive statistics to make inferences about a population based on sample data. It is a statistical method that uses sample data to evaluate a hypothesis about a population.
This type of test is usually used within the context of research. If we expect to see a difference between a treated and untreated group (in some cases the untreated group is the parameters we know about the population), we expect there to be a difference in the means between the two groups, but that the standard deviation remains the same, as if each individual score has had a value added or subtracted from it.
Steps of Hypothesis Testing
The following steps will be tailored to fit the first kind of hypothesis testing we will learn first: single-sample z-tests. There are many other kinds of tests, so keep this in mind.
- Null Hypothesis (H0): states that in the general population there is no change, no difference, or no relationship, or in the context of an experiment, it predicts that the independent variable has no effect on the dependent variable.
- Alternative Hypothesis (H1): states that there is a change, a difference, or a relationship for the general population, or in the context of an experiment, it predicts that the independent variable has an effect on the dependent variable.

- Critical Region: Composed of the extreme sample values that are very unlikely to be obtained if the null hypothesis is true. Determined by alpha level. If sample data fall in the critical region, the null hypothesis is rejected, because it’s very unlikely they’ve fallen there by chance.
- After collecting the data, we find the sample mean. Now we can compare the sample mean with the null hypothesis by computing a z-score that describes where the sample mean is located relative to the hypothesized population mean. We use the z-score formula.
- We decided previously what the two z-score boundaries are for a critical score. If the z-score we get after plugging the numbers in the aforementioned equation is outside of that critical region, we reject the null hypothesis. Otherwise, we would say that we failed to reject the null hypothesis.
Regions of the Distribution
Because we’re making judgments based on probability and proportion, our normal distributions and certain regions within them come into play.
The Critical Region is composed of the extreme sample values that are very unlikely to be obtained if the null hypothesis is true. Determined by alpha level. If sample data fall in the critical region, the null hypothesis is rejected, because it’s very unlikely they’ve fallen there by chance.
These regions come into play when talking about different errors.
A Type I Error occurs when a researcher rejects a null hypothesis that is actually true; the researcher concludes that a treatment has an effect when it actually doesn’t. This happens when a researcher unknowingly obtains an extreme, non-representative sample. This goes back to alpha level: it’s the probability that the test will lead to a Type I error if the null hypothesis is true.

A result is said to be significant or statistically significant if it is very unlikely to occur when the null hypothesis is true. That is, the result is sufficient to reject the null hypothesis. For instance, two means can be significantly different from one another.
Factors that Influence and Assumptions of Hypothesis Testing
Assumptions of Hypothesis Testing:
- Random sampling: it is assumed that the participants used in the study were selected randomly so that we can confidently generalize our findings from the sample to the population.
- Independent observation: two observations are independent if there is no consistent, predictable relationship between the first observation and the second. The value of σ is unchanged by the treatment; if the population standard deviation is unknown, we assume that the standard deviation for the unknown population (after treatment) is the same as it was for the population before treatment. There are ways of checking to see if this is true in SPSS or Excel.
- Normal sampling distribution: in order to use the unit normal table to identify the critical region, we need the distribution of sample means to be normal (which means we need the population to be distributed normally and/or each sample size needs to be 30 or greater based on what we know about the central limit theorem).
Factors that influence hypothesis testing:
- The variability of the scores, which is measured by either the standard deviation or the variance. The variability influences the size of the standard error in the denominator of the z-score.
- The number of scores in the sample. This value also influences the size of the standard error in the denominator.
Test statistic: indicates that the sample data are converted into a single, specific statistic that is used to test the hypothesis (in this case, the z-score statistic).
Directional Hypotheses and Tailed Tests
In a directional hypothesis test , also known as a one-tailed test, the statistical hypotheses specify with an increase or decrease in the population mean. That is, they make a statement about the direction of the effect.
The Hypotheses for a Directional Test:
- H0: The test scores are not increased/decreased (the treatment doesn’t work)
- H1: The test scores are increased/decreased (the treatment works as predicted)
Because we’re only worried about scores that are either greater or less than the scores predicted by the null hypothesis, we only worry about what’s going on in one tail meaning that the critical region only exists within one tail. This means that all of the alpha is contained in one tail rather than split up into both (so the whole 5% is located in the tail we care about, rather than 2.5% in each tail). So before, we cared about what’s going on at the 0.025 mark of the unit normal table to look at both tails, but now we care about 0.05 because we’re only looking at one tail.
A one-tailed test allows you to reject the null hypothesis when the difference between the sample and the population is relatively small, as long as that difference is in the direction that you predicted. A two-tailed test, on the other hand, requires a relatively large difference independent of direction. In practice, researchers hypothesize using a one-tailed method but base their findings off of whether the results fall into the critical region of a two-tailed method. For the purposes of this class, make sure to calculate your results using the test that is specified in the problem.
Effect Size
A measure of effect size is intended to provide a measurement of the absolute magnitude of a treatment effect, independent of the size of the sample(s) being used. Usually done with Cohen’s d. If you imagine the two distributions, they’re layered over one another. The more they overlap, the smaller the effect size (the means of the two distributions are close). The more they are spread apart, the greater the effect size (the means of the two distributions are farther apart).
Statistical Power
The power of a statistical test is the probability that the test will correctly reject a false null hypothesis. It’s usually what we’re hoping to get when we run an experiment. It’s displayed in the table posted above. Power and effect size are connected. So, we know that the greater the distance between the means, the greater the effect size. If the two distributions overlapped very little, there would be a greater chance of selecting a sample that leads to rejecting the null hypothesis.
This chapter was originally posted to the Math Support Center blog at the University of Baltimore on June 11, 2019.
Math and Statistics Guides from UB's Math & Statistics Center Copyright © by Jenna Lehmann is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Become a Problem-solving School
Or search by topic
Number and algebra.
- Place value and the number system
- Fractions, decimals, percentages, ratio and proportion
- Calculations and numerical methods
- Algebraic expressions, equations and formulae
- Coordinates, functions and graphs
- Patterns, sequences and structure
- Properties of numbers
Geometry and measure
- 3D geometry, shape and space
- Transformations and constructions
- Vectors and matrices
- Measuring and calculating with units
- Pythagoras and trigonometry
- Angles, polygons, and geometrical proof
Probability and statistics
- Handling, processing and representing data
- Probability (spec_group)
Working mathematically
- Thinking mathematically
- Mathematical mindsets
Advanced mathematics
- Decision mathematics and combinatorics
- Advanced probability and statistics
For younger learners
- Early years foundation stage
What is a hypothesis test?
The null hypothesis significance testing (nhst) framework, our simple scenario.
- Our null hypothesis is $H_0\colon \pi=\frac{1}{2}$. This says that the proportion is what we believe it should be.
- Our alternative hypothesis is $H_1\colon \pi\ne\frac{1}{2}$. This says that the proportion has changed.
Testing our hypotheses
- We can work out the critical region for $X$, that is, those extreme values of $X$ which would lead us to reject the null hypothesis at 5% significance. (This can be done even before performing the experiment.) The probability of $X$ taking a value in this critical region, assuming that the null hypothesis is true, should be 5%, or as close at we can get to 5% without going over it. In symbols, we can say: $$\mathrm{P}(\text{$X$ in critical region} | \text{$H_0$ is true}) \le 0.05.$$ Then we reject the null hypothesis if $X$ lies in that region.
- We can work out the probability of $X$ taking the value it did or a more extreme value, assuming that the null hypothesis is true. This is known as the p-value . If the p-value is less than 0.05, then we will reject the null hypothesis at 5% significance. [ note 1 ] In symbols, we can write $$\text{p-value} = \mathrm{P}(\text{$X$ taking this or a more extreme value} | \text{$H_0$ is true}).$$
Other types of scenario
- Does this drug/treatment/intervention/... have any effect?
- Which of these drugs/... is more effective, or are they equally effective?
- Is the mean height/mass/intelligence/test score/... of this population equal to some predicted value?
- Is the standard deviation of the height/mass/... equal to some predicted value?
- For two distinct groups of people, is their mean height/mass/... of each group the same?
- Does this group of people's heights/masses/... appear to be following the probability distribution we expect?
- Do these two populations' heights/masses/... appear to have the same distribution as each other?
- Do this population's heights and weights appear to be correlated?
Interpreting the results
The key question that hypothesis testing (nhst) answers, what a hypothesis test does not tell us, a non-significant result.
- It could be that the null hypothesis is true. In this case, we would have to be unlucky to get a significant p-value, so most of the time, we will end up accepting the null hypothesis. (If the null hypothesis is true, we would reject it with a probability of only 0.05.)
- On the other hand, it could be that the alternative hypothesis is true, but we did not use a large enough sample to obtain a significant result (or we were just unlucky). In such a case, we could say that our test was insensitive . In this situation (the alternative hypothesis is true but we do not reject the null hypothesis), we say that we have made a Type II error . The probability of this happening depends on the sample size and on how different the true $\pi$ is from $\frac{1}{2}$ (or whatever our null hypothesis says), as is explored in Powerful Hypothesis Testing .
A significant result
- It could be that the null hypothesis is true. In this case, we reject the null hypothesis with a probability of $0.05=\frac{1}{20}$, that is, one time in 20 (at a significance level of 5%), so we were just unlucky.
- On the other hand, the alternative hypothesis could indeed be true. Either the sample was large enough to obtain a significant result, or the sample size wasn't that large, but we were just lucky.
Using this tree diagram, we can work out the probabilities of $H_0$ being true or $H_1$ being true given our experimental results. To avoid the expressions becoming unwieldy, we will write $H_0$ for "$\text{$H_0$ true}$", $H_1$ for "$\text{$H_1$ true}$" and "$\text{p}^+$" for "observed p-value or more extreme". Then we can write (conditional) probabilities on the branches of the tree diagram leading to our observed p-value: [ note 2 ]
The two routes which give our observed p-value (or more extreme) have the following probabilities: $$\begin{align*} \mathrm{P}(H_0\cap \text{p}^+) &= \mathrm{P}(H_0) \times \mathrm{P}(\text{p}^+ | H_0) \\ \mathrm{P}(H_1\cap \text{p}^+) &= \mathrm{P}(H_1) \times \mathrm{P}(\text{p}^+ | H_1) \end{align*}$$ (Recall that $\mathrm{P}(H_0\cap \text{p}^+)$ means "the probability of $H_0$ being true and the p-value being that observed or more extreme".) We can therefore work out the probability of the alternative hypothesis being true given the observed p-value, using conditional probability: $$\begin{align*} \mathrm{P}(H_1|\text{p}^+) &= \frac{\mathrm{P}(H_1\cap \text{p}^+)}{\mathrm{P}(\text{p}^+)} \\ &= \frac{\mathrm{P}(H_1\cap \text{p}^+)}{\mathrm{P}(H_0\cap\text{p}^+)+\mathrm{P}(H_1\cap\text{p}^+)} \\ &= \frac{\mathrm{P}(H_1) \times \mathrm{P}(\text{p}^+ | H_1)}{\mathrm{P}(H_0) \times \mathrm{P}(\text{p}^+ | H_0) + \mathrm{P}(H_1) \times \mathrm{P}(\text{p}^+ | H_1)} \end{align*}$$ Though this is a mouthful, it is a calculation which only involves the four probabilities on the above tree diagram. (This is an example of Bayes' Theorem , discussed further in this resource .) However, we immediately hit a big difficulty if we try to calculate this for a given experiment. We know $\mathrm{P}(\text{p}^+ | H_0)$: this is just the p-value itself. (The p-value tells us the probability of obtaining a result at least this extreme given that the null hypothesis is true.) But we don't know the probability of the null hypothesis being true or false (that is, $\mathrm{P}(H_0)$ and $\mathrm{P}(H_1)=1-\mathrm{P}(H_0)$), nor do we know the probability of the observed result if the alternative hypothesis is true ($P(\text{p}^+|H_1)$), as knowing that the proportion of greens is not $\frac{1}{2}$ does not tell us what it actually is. (Similar issues apply to all the other contexts of hypothesis testing listed above.) So we are quite stuck: in the null hypothesis significance testing model, it is impossible to give a numerical answer to our key question: "Given our results, what is the probability that the alternative hypothesis is true?" This is because we don't know two of the three probabilities that we need in order to answer the question. An example might highlight the issue a little better. Let us suppose that we are trying to work out whether a coin is biased (alternative hypothesis), or whether the probability of heads is exactly $\frac{1}{2}$ (null hypothesis). We toss the coin 50 times and obtain a p-value of 0.02. Do we now believe that the coin is biased? Most people believe that coins are not biased, and so are much more likely to attribute this result to chance or poor coin-tossing technique than to the coin being biased. On the other hand, consider a case of a road planner who introduces a traffic-calming feature to reduce the number of fatalities along a certain stretch of road. The null hypothesis is that there is no change in fatality rate, while the alternative hypothesis is that the fatality rate has decreased. A hypothesis test is performed on data collected for 24 months before and 24 months after the feature is built. Again, the p-value was 0.02. Do we believe that the alternative hypothesis is true? In this case, we are more likely to believe that the alternative hypothesis is true, because it makes a lot of sense that this feature will reduce the number of fatalities. Our "instinctive" responses to these results are tied up with assigning values to the unknown probabilities in the formula above. For the coin, we would probably take $\mathrm{P}(H_0)$ to be close to 1, say $0.99$, as we think it is very unlikely that the coin is biased, and $\mathrm{P}(\text{p}^+|H_1)$ will be, say, $0.1$: if the coin is biased, the bias is not likely to be very large, and so it is only a bit more likely that the result will be significant in this case. Putting these figures into the formula above gives: $$\mathrm{P}(H_1|\text{p}^+) = \frac{0.01 \times 0.1}{0.99 \times 0.02 + 0.01 \times 0.1} \approx 0.05,$$ that is, we are still very doubtful that this coin is biased, even after performing the experiment. Note that in this case, the probability of these results given that the null hypothesis is true is 0.02, whereas the probability that the null hypothesis is true given these results is $1-0.05=0.95$, which is very different. This shows how dramatically different the answers to the two questions can be. On the other hand, for the fatalities situation, we might assume quite the opposite: we are pretty confident that the traffic-calming feature will help, so we might take $\mathrm{P}(H_0)$ to be $0.4$, and $\mathrm{P}(\text{p}^+|H_1)$ will be, say, $0.25$ (though the traffic-calming may help, the impact may be relatively small). Putting these figures into the formula gives: $$\mathrm{P}(H_1|\text{p}^+) = \frac{0.6 \times 0.25}{0.4 \times 0.02 + 0.6 \times 0.25} \approx 0.95,$$ so we are now much more convinced that the traffic-calming feature is helping than we were before we had the data. This time, the probability of these results given that the null hypothesis is true is still 0.02, whereas the probability that the null hypothesis is true given these results is $1-0.95=0.05$, which is not that different. This approach may seem very disturbing, as we have to make assumptions about what we believe before we do the hypothesis test. But as we have seen, we cannot answer our key question without making such assumptions.
Other approaches and some warnings
- Because our test is two-tailed (in the alternative hypothesis, the true proportion could be less than $\frac{1}{2}$ or more than $\frac{1}{2}$), we must be careful when calculating the p-value: we calculate the probability of the observed outcome or more extreme occurring, and then double the answer to account for the other tail. We could also compare the probability of the value or more extreme to 0.025 instead of 0.05, but that would not be called a p-value. Likewise, when we determine the critical region, we will have two parts: a tail with large values of $X$ and a tail with small values of $X$; we require that the probability of $X$ lying in the large-value tail is as close as possible to 0.025 without going over it, and the same for the probability of $X$ lying in the small-value tail.
- There are complications here when working with two-tail tests as opposed to one-tail tests. We will ignore this problem, as it does not significantly affect the overall discussion.
- "Likelihood" is a technical term. For a discrete test statistic $X$, the likelihood of $H_0$ given the data $X=x$ means $P(X=x|H_0)$, in other words, how likely would this data be if $H_0$ were true. It is not the probability of $H_0$ being true given the data.
Further reading
Professor: Erika L.C. King Email: [email protected] Office: Lansing 304 Phone: (315)781-3355
The majority of statements in mathematics can be written in the form: "If A, then B." For example: "If a function is differentiable, then it is continuous". In this example, the "A" part is "a function is differentiable" and the "B" part is "a function is continuous." The "A" part of the statement is called the "hypothesis", and the "B" part of the statement is called the "conclusion". Thus the hypothesis is what we must assume in order to be positive that the conclusion will hold.
Whenever you are asked to state a theorem, be sure to include the hypothesis. In order to know when you may apply the theorem, you need to know what constraints you have. So in the example above, if we know that a function is differentiable, we may assume that it is continuous. However, if we do not know that a function is differentiable, continuity may not hold. Some theorems have MANY hypotheses, some of which are written in sentences before the ultimate "if, then" statement. For example, there might be a sentence that says: "Assume n is even." which is then followed by an if,then statement. Include all hypotheses and assumptions when asked to state theorems and definitions!
Still have questions? Please ask!
- Mathematicians
- Math Lessons
- Square Roots
- Math Calculators
- Hypothesis | Definition & Meaning
JUMP TO TOPIC
Explanation of Hypothesis
Contradiction, simple hypothesis, complex hypothesis, null hypothesis, alternative hypothesis, empirical hypothesis, statistical hypothesis, special example of hypothesis, solution part (a), solution part (b), hypothesis|definition & meaning.
A hypothesis is a claim or statement that makes sense in the context of some information or data at hand but hasn’t been established as true or false through experimentation or proof.
In mathematics, any statement or equation that describes some relationship between certain variables can be termed as hypothesis if it is consistent with some initial supporting data or information, however, its yet to be proven true or false by some definite and trustworthy experiment or mathematical law.
Following example illustrates one such hypothesis to shed some light on this very fundamental concept which is often used in different areas of mathematics.

Figure 1: Example of Hypothesis
Here we have considered an example of a young startup company that manufactures state of the art batteries. The hypothesis or the claim of the company is that their batteries have a mean life of more than 1000 hours. Now its very easy to understand that they can prove their claim on some testing experiment in their lab.
However, the statement can only be proven if and only if at least one batch of their production batteries have actually been deployed in the real world for more than 1000 hours . After 1000 hours, data needs to be collected and it needs to be seen what is the probability of this statement being true .
The following paragraphs further explain this concept.
As explained with the help of an example earlier, a hypothesis in mathematics is an untested claim that is backed up by all the known data or some other discoveries or some weak experiments.
In any mathematical discovery, we first start by assuming something or some relationship . This supposed statement is called a supposition. A supposition, however, becomes a hypothesis when it is supported by all available data and a large number of contradictory findings.
The hypothesis is an important part of the scientific method that is widely known today for making new discoveries. The field of mathematics inherited this process. Following figure shows this cycle as a graphic:

Figure 2: Role of Hypothesis in the Scientific Method
The above figure shows a simplified version of the scientific method. It shows that whenever a supposition is supported by some data, its termed as hypothesis. Once a hypothesis is proven by some well known and widely acceptable experiment or proof, its becomes a law. If the hypothesis is rejected by some contradictory results then the supposition is changed and the cycle continues.
Lets try to understand the scientific method and the hypothesis concept with the help of an example. Lets say that a teacher wanted to analyze the relationship between the students performance in a certain subject, lets call it A, based on whether or not they studied a minor course, lets call it B.
Now the teacher puts forth a supposition that the students taking the course B prior to course A must perform better in the latter due to the obvious linkages in the key concepts. Due to this linkage, this supposition can be termed as a hypothesis.
However to test the hypothesis, the teacher has to collect data from all of his/her students such that he/she knows which students have taken course B and which ones haven’t. Then at the end of the semester, the performance of the students must be measured and compared with their course B enrollments.
If the students that took course B prior to course A perform better, then the hypothesis concludes successful . Otherwise, the supposition may need revision.
The following figure explains this problem graphically.

Figure 3: Teacher and Course Example of Hypothesis
Important Terms Related to Hypothesis
To further elaborate the concept of hypothesis, we first need to understand a few key terms that are widely used in this area such as conjecture, contradiction and some special types of hypothesis (simple, complex, null, alternative, empirical, statistical). These terms are briefly explained below:
A conjecture is a term used to describe a mathematical assertion that has notbeenproved. While testing may occasionally turn up millions of examples in favour of a conjecture, most experts in the area will typically only accept a proof . In mathematics, this term is synonymous to the term hypothesis.
In mathematics, a contradiction occurs if the results of an experiment or proof are against some hypothesis. In other words, a contradiction discredits a hypothesis.
A simple hypothesis is such a type of hypothesis that claims there is a correlation between two variables. The first is known as a dependent variable while the second is known as an independent variable.
A complex hypothesis is such a type of hypothesis that claims there is a correlation between more than two variables. Both the dependent and independent variables in this hypothesis may be more than one in numbers.
A null hypothesis, usually denoted by H0, is such a type of hypothesis that claims there is no statistical relationship and significance between two sets of observed data and measured occurrences for each set of defined, single observable variables. In short the variables are independent.
An alternative hypothesis, usually denoted by H1 or Ha, is such a type of hypothesis where the variables may be statistically influenced by some unknown factors or variables. In short the variables are dependent on some unknown phenomena .
An Empirical hypothesis is such a type of hypothesis that is built on top of some empirical data or experiment or formulation.
A statistical hypothesis is such a type of hypothesis that is built on top of some statistical data or experiment or formulation. It may be logical or illogical in nature.
According to the Riemann hypothesis, only negative even integers and complex numbers with real part 1/2 have zeros in the Riemann zeta function . It is regarded by many as the most significant open issue in pure mathematics.

Figure 4: Riemann Hypothesis
The Riemann hypothesis is the most well-known mathematical conjecture, and it has been the subject of innumerable proof efforts.
Numerical Examples
Identify the conclusions and hypothesis in the following given statements. Also state if the conclusion supports the hypothesis or not.
Part (a): If 30x = 30, then x = 1
Part (b): if 10x + 2 = 50, then x = 24
Hypothesis: 30x = 30
Conclusion: x = 10
Supports Hypothesis: Yes
Hypothesis: 10x + 2 = 50
Conclusion: x = 24
All images/mathematical drawings were created with GeoGebra.
Hour Hand Definition < Glossary Index > Identity Definition
| Title | hypothesis |
|---|---|
| name | Hypothesis |
| Date of creation | 2013-03-22 17:15:18 |
| Last modified on | 2013-03-22 17:15:18 |
| Owner | PrimeFan (13766) |
| Last modified by | PrimeFan (13766) |
| Numerical id | 6 |
| Author | PrimeFan (13766) |
| Entry type | |
| Classification | msc 00A05 |
Hypothesis Testing
Hypothesis testing is the use of statistics to determine the probability that a given hypothesis is true. The usual process of hypothesis testing consists of four steps.
2. Identify a test statistic that can be used to assess the truth of the null hypothesis .
Explore with Wolfram|Alpha
More things to try:
- hypothesis testing mean
- 1/6 + 5/12 + 3/4
- Dynamic options
Referenced on Wolfram|Alpha
Cite this as:.
Weisstein, Eric W. "Hypothesis Testing." From MathWorld --A Wolfram Web Resource. https://mathworld.wolfram.com/HypothesisTesting.html
Subject classifications
What Is a Hypothesis? (Science)
If...,Then...
Angela Lumsden/Getty Images
- Scientific Method
- Chemical Laws
- Periodic Table
- Projects & Experiments
- Biochemistry
- Physical Chemistry
- Medical Chemistry
- Chemistry In Everyday Life
- Famous Chemists
- Activities for Kids
- Abbreviations & Acronyms
- Weather & Climate
- Ph.D., Biomedical Sciences, University of Tennessee at Knoxville
- B.A., Physics and Mathematics, Hastings College
A hypothesis (plural hypotheses) is a proposed explanation for an observation. The definition depends on the subject.
In science, a hypothesis is part of the scientific method. It is a prediction or explanation that is tested by an experiment. Observations and experiments may disprove a scientific hypothesis, but can never entirely prove one.
In the study of logic, a hypothesis is an if-then proposition, typically written in the form, "If X , then Y ."
In common usage, a hypothesis is simply a proposed explanation or prediction, which may or may not be tested.
Writing a Hypothesis
Most scientific hypotheses are proposed in the if-then format because it's easy to design an experiment to see whether or not a cause and effect relationship exists between the independent variable and the dependent variable . The hypothesis is written as a prediction of the outcome of the experiment.
Null Hypothesis and Alternative Hypothesis
Statistically, it's easier to show there is no relationship between two variables than to support their connection. So, scientists often propose the null hypothesis . The null hypothesis assumes changing the independent variable will have no effect on the dependent variable.
In contrast, the alternative hypothesis suggests changing the independent variable will have an effect on the dependent variable. Designing an experiment to test this hypothesis can be trickier because there are many ways to state an alternative hypothesis.
For example, consider a possible relationship between getting a good night's sleep and getting good grades. The null hypothesis might be stated: "The number of hours of sleep students get is unrelated to their grades" or "There is no correlation between hours of sleep and grades."
An experiment to test this hypothesis might involve collecting data, recording average hours of sleep for each student and grades. If a student who gets eight hours of sleep generally does better than students who get four hours of sleep or 10 hours of sleep, the hypothesis might be rejected.
But the alternative hypothesis is harder to propose and test. The most general statement would be: "The amount of sleep students get affects their grades." The hypothesis might also be stated as "If you get more sleep, your grades will improve" or "Students who get nine hours of sleep have better grades than those who get more or less sleep."
In an experiment, you can collect the same data, but the statistical analysis is less likely to give you a high confidence limit.
Usually, a scientist starts out with the null hypothesis. From there, it may be possible to propose and test an alternative hypothesis, to narrow down the relationship between the variables.
Example of a Hypothesis
Examples of a hypothesis include:
- If you drop a rock and a feather, (then) they will fall at the same rate.
- Plants need sunlight in order to live. (if sunlight, then life)
- Eating sugar gives you energy. (if sugar, then energy)
- White, Jay D. Research in Public Administration . Conn., 1998.
- Schick, Theodore, and Lewis Vaughn. How to Think about Weird Things: Critical Thinking for a New Age . McGraw-Hill Higher Education, 2002.
- Scientific Method Flow Chart
- Six Steps of the Scientific Method
- What Are the Elements of a Good Hypothesis?
- What Are Examples of a Hypothesis?
- What Is a Testable Hypothesis?
- Null Hypothesis Examples
- Scientific Hypothesis Examples
- Scientific Variable
- Scientific Method Vocabulary Terms
- Understanding Simple vs Controlled Experiments
- What Is an Experimental Constant?
- What Is a Controlled Experiment?
- What Is the Difference Between a Control Variable and Control Group?
- DRY MIX Experiment Variables Acronym
- Random Error vs. Systematic Error
- The Role of a Controlled Variable in an Experiment
Hypothesis test
A significance test, also referred to as a statistical hypothesis test, is a method of statistical inference in which observed data is compared to a claim (referred to as a hypothesis) in order to assess the truth of the claim. For example, one might wonder whether age affects the number of apples a person can eat, and may use a significance test to determine whether there is any evidence to suggest that it does.
Generally, the process of statistical hypothesis testing involves the following steps:
- State the null hypothesis.
- State the alternative hypothesis.
- Select the appropriate test statistic and select a significance level.
- Compute the observed value of the test statistic and its corresponding p-value.
- Reject the null hypothesis in favor of the alternative hypothesis, or do not reject the null hypothesis.
The null hypothesis
The null hypothesis, H 0 , is the claim that is being tested in a statistical hypothesis test. It typically is a statement that there is no difference between the populations being studied, or that there is no evidence to support a claim being made. For example, "age has no effect on the number of apples a person can eat."
A significance test is designed to test the evidence against the null hypothesis. This is because it is easier to prove that a claim is false than to prove that it is true; demonstrating that the claim is false in one case is sufficient, while proving that it is true requires that the claim be true in all cases.
The alternative hypothesis
The alternative hypothesis is the opposite of the null hypothesis in that it is a statement that there is some difference between the populations being studied. For example, "younger people can eat more apples than older people."
The alternative hypothesis is typically the hypothesis that researchers are trying to prove. A significance test is meant to determine whether there is sufficient evidence to reject the null hypothesis in favor of the alternative hypothesis. Note that the results of a significance test should either be to reject the null hypothesis in favor of the alternative hypothesis, or to not reject the null hypothesis. The result should not be to reject the alternative hypothesis or to accept the alternative hypothesis.
Test statistics and significance level
A test statistic is a statistic that is calculated as part of hypothesis testing that compares the distribution of observed data to the expected distribution, based on the null hypothesis. Examples of test statistics include the Z-score, T-statistic, F-statistic, and the Chi-square statistic. The test statistic used is dependent on the significance test used, which is dependent on the type of data collected and the type of relationship to be tested.
In many cases, the chosen significance level is 0.05, though 0.01 is also used. A significance level of 0.05 indicates that there is a 5% chance of rejecting the null hypothesis when the null hypothesis is actually true. Thus, a smaller selected significance level will require more evidence if the null hypothesis is to be rejected in favor of the alternative hypothesis.
After the test statistic is computed, the p-value can be determined based on the result of the test statistic. The p-value indicates the probability of obtaining test results that are at least as extreme as the observed results, under the assumption that the null hypothesis is correct. It tells us how likely it is to obtain a result based solely on chance. The smaller the p-value, the less likely a result can occur purely by chance, while a larger p-value makes it more likely. For example, a p-value of 0.01 means that there is a 1% chance that a result occurred solely by chance, given that the null hypothesis is true; a p-value of 0.90 means that there is a 90% chance.
A p-value is significantly affected by sample size. The larger the sample size, the smaller the p-value, even if the difference between populations may not be meaningful. On the other hand, if a sample size is too small, a meaningful difference may not be detected.
The last step in a significance test is to determine whether the p-value provides evidence that the null hypothesis should be rejected in favor of the alternative hypothesis. This is based on the selected significance level. If the p-value is less than or equal to the selected significance level, the null hypothesis is rejected in favor of the alternative hypothesis, and the result is deemed statistically significant. If the p-value is greater than the selected significance level, the null hypothesis is not rejected, and the result is deemed not statistically significant.
- Math Article
Null Hypothesis

In mathematics, Statistics deals with the study of research and surveys on the numerical data. For taking surveys, we have to define the hypothesis. Generally, there are two types of hypothesis. One is a null hypothesis, and another is an alternative hypothesis .
In probability and statistics, the null hypothesis is a comprehensive statement or default status that there is zero happening or nothing happening. For example, there is no connection among groups or no association between two measured events. It is generally assumed here that the hypothesis is true until any other proof has been brought into the light to deny the hypothesis. Let us learn more here with definition, symbol, principle, types and example, in this article.
Table of contents:
- Comparison with Alternative Hypothesis
Null Hypothesis Definition
The null hypothesis is a kind of hypothesis which explains the population parameter whose purpose is to test the validity of the given experimental data. This hypothesis is either rejected or not rejected based on the viability of the given population or sample . In other words, the null hypothesis is a hypothesis in which the sample observations results from the chance. It is said to be a statement in which the surveyors wants to examine the data. It is denoted by H 0 .
Null Hypothesis Symbol
In statistics, the null hypothesis is usually denoted by letter H with subscript ‘0’ (zero), such that H 0 . It is pronounced as H-null or H-zero or H-nought. At the same time, the alternative hypothesis expresses the observations determined by the non-random cause. It is represented by H 1 or H a .
Null Hypothesis Principle
The principle followed for null hypothesis testing is, collecting the data and determining the chances of a given set of data during the study on some random sample, assuming that the null hypothesis is true. In case if the given data does not face the expected null hypothesis, then the outcome will be quite weaker, and they conclude by saying that the given set of data does not provide strong evidence against the null hypothesis because of insufficient evidence. Finally, the researchers tend to reject that.
Null Hypothesis Formula
Here, the hypothesis test formulas are given below for reference.
The formula for the null hypothesis is:
H 0 : p = p 0
The formula for the alternative hypothesis is:
H a = p >p 0 , < p 0 ≠ p 0
The formula for the test static is:
Remember that, p 0 is the null hypothesis and p – hat is the sample proportion.
Also, read:
Types of Null Hypothesis
There are different types of hypothesis. They are:
Simple Hypothesis
It completely specifies the population distribution. In this method, the sampling distribution is the function of the sample size.
Composite Hypothesis
The composite hypothesis is one that does not completely specify the population distribution.
Exact Hypothesis
Exact hypothesis defines the exact value of the parameter. For example μ= 50
Inexact Hypothesis
This type of hypothesis does not define the exact value of the parameter. But it denotes a specific range or interval. For example 45< μ <60
Null Hypothesis Rejection
Sometimes the null hypothesis is rejected too. If this hypothesis is rejected means, that research could be invalid. Many researchers will neglect this hypothesis as it is merely opposite to the alternate hypothesis. It is a better practice to create a hypothesis and test it. The goal of researchers is not to reject the hypothesis. But it is evident that a perfect statistical model is always associated with the failure to reject the null hypothesis.
How do you Find the Null Hypothesis?
The null hypothesis says there is no correlation between the measured event (the dependent variable) and the independent variable. We don’t have to believe that the null hypothesis is true to test it. On the contrast, you will possibly assume that there is a connection between a set of variables ( dependent and independent).
When is Null Hypothesis Rejected?
The null hypothesis is rejected using the P-value approach. If the P-value is less than or equal to the α, there should be a rejection of the null hypothesis in favour of the alternate hypothesis. In case, if P-value is greater than α, the null hypothesis is not rejected.
Null Hypothesis and Alternative Hypothesis
Now, let us discuss the difference between the null hypothesis and the alternative hypothesis.
|
|
| |
| 1 | The null hypothesis is a statement. There exists no relation between two variables | Alternative hypothesis a statement, there exists some relationship between two measured phenomenon |
| 2 | Denoted by H | Denoted by H |
| 3 | The observations of this hypothesis are the result of chance | The observations of this hypothesis are the result of real effect |
| 4 | The mathematical formulation of the null hypothesis is an equal sign | The mathematical formulation alternative hypothesis is an inequality sign such as greater than, less than, etc. |
Null Hypothesis Examples
Here, some of the examples of the null hypothesis are given below. Go through the below ones to understand the concept of the null hypothesis in a better way.
If a medicine reduces the risk of cardiac stroke, then the null hypothesis should be “the medicine does not reduce the chance of cardiac stroke”. This testing can be performed by the administration of a drug to a certain group of people in a controlled way. If the survey shows that there is a significant change in the people, then the hypothesis is rejected.
Few more examples are:
1). Are there is 100% chance of getting affected by dengue?
Ans: There could be chances of getting affected by dengue but not 100%.
2). Do teenagers are using mobile phones more than grown-ups to access the internet?
Ans: Age has no limit on using mobile phones to access the internet.
3). Does having apple daily will not cause fever?
Ans: Having apple daily does not assure of not having fever, but increases the immunity to fight against such diseases.
4). Do the children more good in doing mathematical calculations than grown-ups?
Ans: Age has no effect on Mathematical skills.
In many common applications, the choice of the null hypothesis is not automated, but the testing and calculations may be automated. Also, the choice of the null hypothesis is completely based on previous experiences and inconsistent advice. The choice can be more complicated and based on the variety of applications and the diversity of the objectives.
The main limitation for the choice of the null hypothesis is that the hypothesis suggested by the data is based on the reasoning which proves nothing. It means that if some hypothesis provides a summary of the data set, then there would be no value in the testing of the hypothesis on the particular set of data.
Frequently Asked Questions on Null Hypothesis
What is meant by the null hypothesis.
In Statistics, a null hypothesis is a type of hypothesis which explains the population parameter whose purpose is to test the validity of the given experimental data.
What are the benefits of hypothesis testing?
Hypothesis testing is defined as a form of inferential statistics, which allows making conclusions from the entire population based on the sample representative.
When a null hypothesis is accepted and rejected?
The null hypothesis is either accepted or rejected in terms of the given data. If P-value is less than α, then the null hypothesis is rejected in favor of the alternative hypothesis, and if the P-value is greater than α, then the null hypothesis is accepted in favor of the alternative hypothesis.
Why is the null hypothesis important?
The importance of the null hypothesis is that it provides an approximate description of the phenomena of the given data. It allows the investigators to directly test the relational statement in a research study.
How to accept or reject the null hypothesis in the chi-square test?
If the result of the chi-square test is bigger than the critical value in the table, then the data does not fit the model, which represents the rejection of the null hypothesis.

Put your understanding of this concept to test by answering a few MCQs. Click ‘Start Quiz’ to begin!
Select the correct answer and click on the “Finish” button Check your score and answers at the end of the quiz
Visit BYJU’S for all Maths related queries and study materials
Your result is as below
Request OTP on Voice Call
| MATHS Related Links | |
Register with BYJU'S & Download Free PDFs
Register with byju's & watch live videos.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Hypothesis Testing | A Step-by-Step Guide with Easy Examples
Published on November 8, 2019 by Rebecca Bevans . Revised on June 22, 2023.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics . It is most often used by scientists to test specific predictions, called hypotheses, that arise from theories.
There are 5 main steps in hypothesis testing:
- State your research hypothesis as a null hypothesis and alternate hypothesis (H o ) and (H a or H 1 ).
- Collect data in a way designed to test the hypothesis.
- Perform an appropriate statistical test .
- Decide whether to reject or fail to reject your null hypothesis.
- Present the findings in your results and discussion section.
Though the specific details might vary, the procedure you will use when testing a hypothesis will always follow some version of these steps.
Table of contents
Step 1: state your null and alternate hypothesis, step 2: collect data, step 3: perform a statistical test, step 4: decide whether to reject or fail to reject your null hypothesis, step 5: present your findings, other interesting articles, frequently asked questions about hypothesis testing.
After developing your initial research hypothesis (the prediction that you want to investigate), it is important to restate it as a null (H o ) and alternate (H a ) hypothesis so that you can test it mathematically.
The alternate hypothesis is usually your initial hypothesis that predicts a relationship between variables. The null hypothesis is a prediction of no relationship between the variables you are interested in.
- H 0 : Men are, on average, not taller than women. H a : Men are, on average, taller than women.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
For a statistical test to be valid , it is important to perform sampling and collect data in a way that is designed to test your hypothesis. If your data are not representative, then you cannot make statistical inferences about the population you are interested in.
There are a variety of statistical tests available, but they are all based on the comparison of within-group variance (how spread out the data is within a category) versus between-group variance (how different the categories are from one another).
If the between-group variance is large enough that there is little or no overlap between groups, then your statistical test will reflect that by showing a low p -value . This means it is unlikely that the differences between these groups came about by chance.
Alternatively, if there is high within-group variance and low between-group variance, then your statistical test will reflect that with a high p -value. This means it is likely that any difference you measure between groups is due to chance.
Your choice of statistical test will be based on the type of variables and the level of measurement of your collected data .
- an estimate of the difference in average height between the two groups.
- a p -value showing how likely you are to see this difference if the null hypothesis of no difference is true.
Based on the outcome of your statistical test, you will have to decide whether to reject or fail to reject your null hypothesis.
In most cases you will use the p -value generated by your statistical test to guide your decision. And in most cases, your predetermined level of significance for rejecting the null hypothesis will be 0.05 – that is, when there is a less than 5% chance that you would see these results if the null hypothesis were true.
In some cases, researchers choose a more conservative level of significance, such as 0.01 (1%). This minimizes the risk of incorrectly rejecting the null hypothesis ( Type I error ).
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

The results of hypothesis testing will be presented in the results and discussion sections of your research paper , dissertation or thesis .
In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p -value). In the discussion , you can discuss whether your initial hypothesis was supported by your results or not.
In the formal language of hypothesis testing, we talk about rejecting or failing to reject the null hypothesis. You will probably be asked to do this in your statistics assignments.
However, when presenting research results in academic papers we rarely talk this way. Instead, we go back to our alternate hypothesis (in this case, the hypothesis that men are on average taller than women) and state whether the result of our test did or did not support the alternate hypothesis.
If your null hypothesis was rejected, this result is interpreted as “supported the alternate hypothesis.”
These are superficial differences; you can see that they mean the same thing.
You might notice that we don’t say that we reject or fail to reject the alternate hypothesis . This is because hypothesis testing is not designed to prove or disprove anything. It is only designed to test whether a pattern we measure could have arisen spuriously, or by chance.
If we reject the null hypothesis based on our research (i.e., we find that it is unlikely that the pattern arose by chance), then we can say our test lends support to our hypothesis . But if the pattern does not pass our decision rule, meaning that it could have arisen by chance, then we say the test is inconsistent with our hypothesis .
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 22). Hypothesis Testing | A Step-by-Step Guide with Easy Examples. Scribbr. Retrieved September 23, 2024, from https://www.scribbr.com/statistics/hypothesis-testing/
Is this article helpful?

Rebecca Bevans
Other students also liked, choosing the right statistical test | types & examples, understanding p values | definition and examples, what is your plagiarism score.
Hypothesis testing
When interpreting research findings, researchers need to assess whether these findings may have occurred by chance. Hypothesis testing is a systematic procedure for deciding whether the results of a research study support a particular theory which applies to a population.
Hypothesis testing uses sample data to evaluate a hypothesis about a population . A hypothesis test assesses how unusual the result is, whether it is reasonable chance variation or whether the result is too extreme to be considered chance variation.
Basic concepts
- Null and research hypothesis
Probability value and types of errors
Effect size and statistical significance.
- Directional and non-directional hypotheses
Null and research hypotheses
To carry out statistical hypothesis testing, research and null hypothesis are employed:
- Research hypothesis : this is the hypothesis that you propose, also known as the alternative hypothesis HA. For example:
H A: There is a relationship between intelligence and academic results.
H A: First year university students obtain higher grades after an intensive Statistics course.
H A; Males and females differ in their levels of stress.
- The null hypothesis (H o ) is the opposite of the research hypothesis and expresses that there is no relationship between variables, or no differences between groups; for example:
H o : There is no relationship between intelligence and academic results.
H o: First year university students do not obtain higher grades after an intensive Statistics course.
H o : Males and females will not differ in their levels of stress.
The purpose of hypothesis testing is to test whether the null hypothesis (there is no difference, no effect) can be rejected or approved. If the null hypothesis is rejected, then the research hypothesis can be accepted. If the null hypothesis is accepted, then the research hypothesis is rejected.
In hypothesis testing, a value is set to assess whether the null hypothesis is accepted or rejected and whether the result is statistically significant:
- A critical value is the score the sample would need to decide against the null hypothesis.
- A probability value is used to assess the significance of the statistical test. If the null hypothesis is rejected, then the alternative to the null hypothesis is accepted.
The probability value, or p value , is the probability of an outcome or research result given the hypothesis. Usually, the probability value is set at 0.05: the null hypothesis will be rejected if the probability value of the statistical test is less than 0.05. There are two types of errors associated to hypothesis testing:
- What if we observe a difference – but none exists in the population?
- What if we do not find a difference – but it does exist in the population?
These situations are known as Type I and Type II errors:
- Type I Error: is the type of error that involves the rejection of a null hypothesis that is actually true (i.e. a false positive).
- Type II Error: is the type of error that occurs when we do not reject a null hypothesis that is false (i.e. a false negative).

These errors cannot be eliminated; they can be minimised, but minimising one type of error will increase the probability of committing the other type.
The probability of making a Type I error depends on the criterion that is used to accept or reject the null hypothesis: the p value or alpha level . The alpha is set by the researcher, usually at .05, and is the chance the researcher is willing to take and still claim the significance of the statistical test.). Choosing a smaller alpha level will decrease the likelihood of committing Type I error.
For example, p<0.05 indicates that there are 5 chances in 100 that the difference observed was really due to sampling error – that 5% of the time a Type I error will occur or that there is a 5% chance that the opposite of the null hypothesis is actually true.
With a p<0.01, there will be 1 chance in 100 that the difference observed was really due to sampling error – 1% of the time a Type I error will occur.
The p level is specified before analysing the data. If the data analysis results in a probability value below the α (alpha) level, then the null hypothesis is rejected; if it is not, then the null hypothesis is not rejected.
When the null hypothesis is rejected, the effect is said to be statistically significant. However, statistical significance does not mean that the effect is important.
A result can be statistically significant, but the effect size may be small. Finding that an effect is significant does not provide information about how large or important the effect is. In fact, a small effect can be statistically significant if the sample size is large enough.
Information about the effect size, or magnitude of the result, is given by the statistical test. For example, the strength of the correlation between two variables is given by the coefficient of correlation, which varies from 0 to 1.
- A hypothesis that states that students who attend an intensive Statistics course will obtain higher grades than students who do not attend would be directional.
- A non-directional hypothesis states that there will be differences between students who attend do or don’t attend an intensive Statistics course, but we don’t know what group will get higher grades than the other. The hypothesis only states that they will obtain different grades.
The hypothesis testing process
The hypothesis testing process can be divided into five steps:
- Restate the research question as research hypothesis and a null hypothesis about the populations.
- Determine the characteristics of the comparison distribution.
- Determine the cut off sample score on the comparison distribution at which the null hypothesis should be rejected.
- Determine your sample’s score on the comparison distribution.
- Decide whether to reject the null hypothesis.
This example illustrates how these five steps can be applied to text a hypothesis:
- Let’s say that you conduct an experiment to investigate whether students’ ability to memorise words improves after they have consumed caffeine.
- The experiment involves two groups of students: the first group consumes caffeine; the second group drinks water.
- Both groups complete a memory test.
- A randomly selected individual in the experimental condition (i.e. the group that consumes caffeine) has a score of 27 on the memory test. The scores of people in general on this memory measure are normally distributed with a mean of 19 and a standard deviation of 4.
- The researcher predicts an effect (differences in memory for these groups) but does not predict a particular direction of effect (i.e. which group will have higher scores on the memory test). Using the 5% significance level, what should you conclude?
Step 1 : There are two populations of interest.
Population 1: People who go through the experimental procedure (drink coffee).
Population 2: People who do not go through the experimental procedure (drink water).
- Research hypothesis: Population 1 will score differently from Population 2.
- Null hypothesis: There will be no difference between the two populations.
Step 2 : We know that the characteristics of the comparison distribution (student population) are:
Population M = 19, Population SD= 4, normally distributed. These are the mean and standard deviation of the distribution of scores on the memory test for the general student population.
Step 3 : For a two-tailed test (the direction of the effect is not specified) at the 5% level (25% at each tail), the cut off sample scores are +1.96 and -1.99.
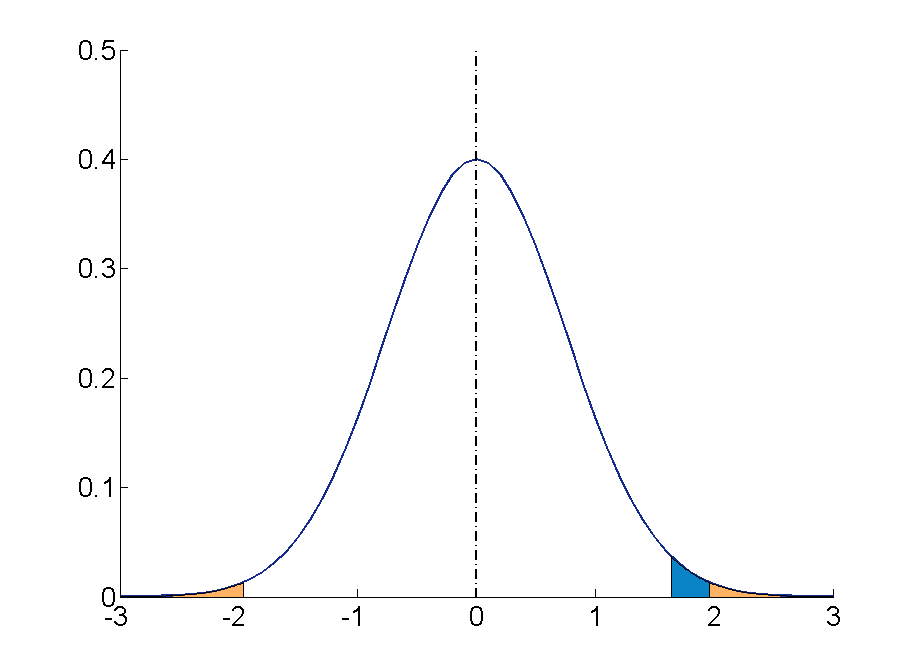
Step 4 : Your sample score of 27 needs to be converted into a Z value. To calculate Z = (27-19)/4= 2 ( check the Converting into Z scores section if you need to review how to do this process)
Step 5 : A ‘Z’ score of 2 is more extreme than the cut off Z of +1.96 (see figure above). The result is significant and, thus, the null hypothesis is rejected.
You can find more examples here:
- Statistics (RMIT Learning Lab)
Some commonly used statistical techniques
Correlation analysis, multiple regression.
- Analysis of variance
Chi-square test for independence
Correlation analysis explores the association between variables . The purpose of correlational analysis is to discover whether there is a relationship between variables, which is unlikely to occur by sampling error. The null hypothesis is that there is no relationship between the two variables. Correlation analysis provides information about:
- The direction of the relationship: positive or negative- given by the sign of the correlation coefficient.
- The strength or magnitude of the relationship between the two variables- given by the correlation coefficient, which varies from 0 (no relationship between the variables) to 1 (perfect relationship between the variables).
- Direction of the relationship.
A positive correlation indicates that high scores on one variable are associated with high scores on the other variable; low scores on one variable are associated with low scores on the second variable . For instance, in the figure below, higher scores on negative affect are associated with higher scores on perceived stress

A negative correlation indicates that high scores on one variable are associated with low scores on the other variable. The graph shows that a person who scores high on perceived stress will probably score low on mastery. The slope of the graph is downwards- as it moves to the right. In the figure below, higher scores on mastery are associated with lower scores on perceived stress.

Fig 2. Negative correlation between two variables. Adapted from Pallant, J. (2013). SPSS survival manual: A step by step guide to data analysis using IBM SPSS (5th ed.). Sydney, Melbourne, Auckland, London: Allen & Unwin
2. The strength or magnitude of the relationship
The strength of a linear relationship between two variables is measured by a statistic known as the correlation coefficient , which varies from 0 to -1, and from 0 to +1. There are several correlation coefficients; the most widely used are Pearson’s r and Spearman’s rho. The strength of the relationship is interpreted as follows:
- Small/weak: r= .10 to .29
- Medium/moderate: r= .30 to .49
- Large/strong: r= .50 to 1
It is important to note that correlation analysis does not imply causality. Correlation is used to explore the association between variables, however, it does not indicate that one variable causes the other. The correlation between two variables could be due to the fact that a third variable is affecting the two variables.
Multiple regression is an extension of correlation analysis. Multiple regression is used to explore the relationship between one dependent variable and a number of independent variables or predictors . The purpose of a multiple regression model is to predict values of a dependent variable based on the values of the independent variables or predictors. For example, a researcher may be interested in predicting students’ academic success (e.g. grades) based on a number of predictors, for example, hours spent studying, satisfaction with studies, relationships with peers and lecturers.
A multiple regression model can be conducted using statistical software (e.g. SPSS). The software will test the significance of the model (i.e. does the model significantly predicts scores on the dependent variable using the independent variables introduced in the model?), how much of the variance in the dependent variable is explained by the model, and the individual contribution of each independent variable.
Example of multiple regression model

From Dunn et al. (2014). Influence of academic self-regulation, critical thinking, and age on online graduate students' academic help-seeking.
In this model, help-seeking is the dependent variable; there are three independent variables or predictors. The coefficients show the direction (positive or negative) and magnitude of the relationship between each predictor and the dependent variable. The model was statistically significant and predicted 13.5% of the variance in help-seeking.
t-Tests are employed to compare the mean score on some continuous variable for two groups . The null hypothesis to be tested is there are no differences between the two groups (e.g. anxiety scores for males and females are not different).
If the significance value of the t-test is equal or less than .05, there is a significant difference in the mean scores on the variable of interest for each of the two groups. If the value is above .05, there is no significant difference between the groups.
t-Tests can be employed to compare the mean scores of two different groups (independent-samples t-test ) or to compare the same group of people on two different occasions ( paired-samples t-test) .
In addition to assessing whether the difference between the two groups is statistically significant, it is important to consider the effect size or magnitude of the difference between the groups. The effect size is given by partial eta squared (proportion of variance of the dependent variable that is explained by the independent variable) and Cohen’s d (difference between groups in terms of standard deviation units).
In this example, an independent samples t-test was conducted to assess whether males and females differ in their perceived anxiety levels. The significance of the test is .004. Since this value is less than .05, we can conclude that there is a statistically significant difference between males and females in their perceived anxiety levels.

Whilst t-tests compare the mean score on one variable for two groups, analysis of variance is used to test more than two groups . Following the previous example, analysis of variance would be employed to test whether there are differences in anxiety scores for students from different disciplines.
Analysis of variance compare the variance (variability in scores) between the different groups (believed to be due to the independent variable) with the variability within each group (believed to be due to chance). An F ratio is calculated; a large F ratio indicates that there is more variability between the groups (caused by the independent variable) than there is within each group (error term). A significant F test indicates that we can reject the null hypothesis; i.e. that there is no difference between the groups.
Again, effect size statistics such as Cohen’s d and eta squared are employed to assess the magnitude of the differences between groups.
In this example, we examined differences in perceived anxiety between students from different disciplines. The results of the Anova Test show that the significance level is .005. Since this value is below .05, we can conclude that there are statistically significant differences between students from different disciplines in their perceived anxiety levels.

Chi-square test for independence is used to explore the relationship between two categorical variables. Each variable can have two or more categories.
For example, a researcher can use a Chi-square test for independence to assess the relationship between study disciplines (e.g. Psychology, Business, Education,…) and help-seeking behaviour (Yes/No). The test compares the observed frequencies of cases with the values that would be expected if there was no association between the two variables of interest. A statistically significant Chi-square test indicates that the two variables are associated (e.g. Psychology students are more likely to seek help than Business students). The effect size is assessed using effect size statistics: Phi and Cramer’s V .
In this example, a Chi-square test was conducted to assess whether males and females differ in their help-seeking behaviour (Yes/No). The crosstabulation table shows the percentage of males of females who sought/didn't seek help. The table 'Chi square tests' shows the significance of the test (Pearson Chi square asymp sig: .482). Since this value is above .05, we conclude that there is no statistically significant difference between males and females in their help-seeking behaviour.

- << Previous: Probability and the normal distribution
- Next: Statistical techniques >>
- School Guide
- Mathematics
- Number System and Arithmetic
- Trigonometry
- Probability
- Mensuration
- Maths Formulas
- Class 8 Maths Notes
- Class 9 Maths Notes
- Class 10 Maths Notes
- Class 11 Maths Notes
- Class 12 Maths Notes
Hypothesis | Definition, Meaning and Examples
Hypothesis is a hypothesis is fundamental concept in the world of research and statistics. It is a testable statement that explains what is happening or observed. It proposes the relation between the various participating variables.
Hypothesis is also called Theory, Thesis, Guess, Assumption, or Suggestion . Hypothesis creates a structure that guides the search for knowledge.
In this article, we will learn what hypothesis is, its characteristics, types, and examples. We will also learn how hypothesis helps in scientific research.
Table of Content
What is Hypothesis?
Characteristics of hypothesis, sources of hypothesis, types of hypothesis, functions of hypothesis, how hypothesis help in scientific research.
Hypothesis is a suggested idea or an educated guess or a proposed explanation made based on limited evidence, serving as a starting point for further study. They are meant to lead to more investigation.
It’s mainly a smart guess or suggested answer to a problem that can be checked through study and trial. In science work, we make guesses called hypotheses to try and figure out what will happen in tests or watching. These are not sure things but rather ideas that can be proved or disproved based on real-life proofs. A good theory is clear and can be tested and found wrong if the proof doesn’t support it.

Hypothesis Meaning
A hypothesis is a proposed statement that is testable and is given for something that happens or observed.
- It is made using what we already know and have seen, and it’s the basis for scientific research.
- A clear guess tells us what we think will happen in an experiment or study.
- It’s a testable clue that can be proven true or wrong with real-life facts and checking it out carefully.
- It usually looks like a “if-then” rule, showing the expected cause and effect relationship between what’s being studied.
Here are some key characteristics of a hypothesis:
- Testable: An idea (hypothesis) should be made so it can be tested and proven true through doing experiments or watching. It should show a clear connection between things.
- Specific: It needs to be easy and on target, talking about a certain part or connection between things in a study.
- Falsifiable: A good guess should be able to show it’s wrong. This means there must be a chance for proof or seeing something that goes against the guess.
- Logical and Rational: It should be based on things we know now or have seen, giving a reasonable reason that fits with what we already know.
- Predictive: A guess often tells what to expect from an experiment or observation. It gives a guide for what someone might see if the guess is right.
- Concise: It should be short and clear, showing the suggested link or explanation simply without extra confusion.
- Grounded in Research: A guess is usually made from before studies, ideas or watching things. It comes from a deep understanding of what is already known in that area.
- Flexible: A guess helps in the research but it needs to change or fix when new information comes up.
- Relevant: It should be related to the question or problem being studied, helping to direct what the research is about.
- Empirical: Hypotheses come from observations and can be tested using methods based on real-world experiences.
Hypotheses can come from different places based on what you’re studying and the kind of research. Here are some common sources from which hypotheses may originate:
- Existing Theories: Often, guesses come from well-known science ideas. These ideas may show connections between things or occurrences that scientists can look into more.
- Observation and Experience: Watching something happen or having personal experiences can lead to guesses. We notice odd things or repeat events in everyday life and experiments. This can make us think of guesses called hypotheses.
- Previous Research: Using old studies or discoveries can help come up with new ideas. Scientists might try to expand or question current findings, making guesses that further study old results.
- Literature Review: Looking at books and research in a subject can help make guesses. Noticing missing parts or mismatches in previous studies might make researchers think up guesses to deal with these spots.
- Problem Statement or Research Question: Often, ideas come from questions or problems in the study. Making clear what needs to be looked into can help create ideas that tackle certain parts of the issue.
- Analogies or Comparisons: Making comparisons between similar things or finding connections from related areas can lead to theories. Understanding from other fields could create new guesses in a different situation.
- Hunches and Speculation: Sometimes, scientists might get a gut feeling or make guesses that help create ideas to test. Though these may not have proof at first, they can be a beginning for looking deeper.
- Technology and Innovations: New technology or tools might make guesses by letting us look at things that were hard to study before.
- Personal Interest and Curiosity: People’s curiosity and personal interests in a topic can help create guesses. Scientists could make guesses based on their own likes or love for a subject.
Here are some common types of hypotheses:
Simple Hypothesis
Complex hypothesis, directional hypothesis.
- Non-directional Hypothesis
Null Hypothesis (H0)
Alternative hypothesis (h1 or ha), statistical hypothesis, research hypothesis, associative hypothesis, causal hypothesis.
Simple Hypothesis guesses a connection between two things. It says that there is a connection or difference between variables, but it doesn’t tell us which way the relationship goes. Example: Studying more can help you do better on tests. Getting more sun makes people have higher amounts of vitamin D.
Complex Hypothesis tells us what will happen when more than two things are connected. It looks at how different things interact and may be linked together. Example: How rich you are, how easy it is to get education and healthcare greatly affects the number of years people live. A new medicine’s success relies on the amount used, how old a person is who takes it and their genes.
Directional Hypothesis says how one thing is related to another. For example, it guesses that one thing will help or hurt another thing. Example: Drinking more sweet drinks is linked to a higher body weight score. Too much stress makes people less productive at work.
Non-Directional Hypothesis
Non-Directional Hypothesis are the one that don’t say how the relationship between things will be. They just say that there is a connection, without telling which way it goes. Example: Drinking caffeine can affect how well you sleep. People often like different kinds of music based on their gender.
Null hypothesis is a statement that says there’s no connection or difference between different things. It implies that any seen impacts are because of luck or random changes in the information. Example: The average test scores of Group A and Group B are not much different. There is no connection between using a certain fertilizer and how much it helps crops grow.
Alternative Hypothesis is different from the null hypothesis and shows that there’s a big connection or gap between variables. Scientists want to say no to the null hypothesis and choose the alternative one. Example: Patients on Diet A have much different cholesterol levels than those following Diet B. Exposure to a certain type of light can change how plants grow compared to normal sunlight.
Statistical Hypothesis are used in math testing and include making ideas about what groups or bits of them look like. You aim to get information or test certain things using these top-level, common words only. Example: The average smarts score of kids in a certain school area is 100. The usual time it takes to finish a job using Method A is the same as with Method B.
Research Hypothesis comes from the research question and tells what link is expected between things or factors. It leads the study and chooses where to look more closely. Example: Having more kids go to early learning classes helps them do better in school when they get older. Using specific ways of talking affects how much customers get involved in marketing activities.
Associative Hypothesis guesses that there is a link or connection between things without really saying it caused them. It means that when one thing changes, it is connected to another thing changing. Example: Regular exercise helps to lower the chances of heart disease. Going to school more can help people make more money.
Causal Hypothesis are different from other ideas because they say that one thing causes another. This means there’s a cause and effect relationship between variables involved in the situation. They say that when one thing changes, it directly makes another thing change. Example: Playing violent video games makes teens more likely to act aggressively. Less clean air directly impacts breathing health in city populations.
Hypotheses have many important jobs in the process of scientific research. Here are the key functions of hypotheses:
- Guiding Research: Hypotheses give a clear and exact way for research. They act like guides, showing the predicted connections or results that scientists want to study.
- Formulating Research Questions: Research questions often create guesses. They assist in changing big questions into particular, checkable things. They guide what the study should be focused on.
- Setting Clear Objectives: Hypotheses set the goals of a study by saying what connections between variables should be found. They set the targets that scientists try to reach with their studies.
- Testing Predictions: Theories guess what will happen in experiments or observations. By doing tests in a planned way, scientists can check if what they see matches the guesses made by their ideas.
- Providing Structure: Theories give structure to the study process by arranging thoughts and ideas. They aid scientists in thinking about connections between things and plan experiments to match.
- Focusing Investigations: Hypotheses help scientists focus on certain parts of their study question by clearly saying what they expect links or results to be. This focus makes the study work better.
- Facilitating Communication: Theories help scientists talk to each other effectively. Clearly made guesses help scientists to tell others what they plan, how they will do it and the results expected. This explains things well with colleagues in a wide range of audiences.
- Generating Testable Statements: A good guess can be checked, which means it can be looked at carefully or tested by doing experiments. This feature makes sure that guesses add to the real information used in science knowledge.
- Promoting Objectivity: Guesses give a clear reason for study that helps guide the process while reducing personal bias. They motivate scientists to use facts and data as proofs or disprovals for their proposed answers.
- Driving Scientific Progress: Making, trying out and adjusting ideas is a cycle. Even if a guess is proven right or wrong, the information learned helps to grow knowledge in one specific area.
Researchers use hypotheses to put down their thoughts directing how the experiment would take place. Following are the steps that are involved in the scientific method:
- Initiating Investigations: Hypotheses are the beginning of science research. They come from watching, knowing what’s already known or asking questions. This makes scientists make certain explanations that need to be checked with tests.
- Formulating Research Questions: Ideas usually come from bigger questions in study. They help scientists make these questions more exact and testable, guiding the study’s main point.
- Setting Clear Objectives: Hypotheses set the goals of a study by stating what we think will happen between different things. They set the goals that scientists want to reach by doing their studies.
- Designing Experiments and Studies: Assumptions help plan experiments and watchful studies. They assist scientists in knowing what factors to measure, the techniques they will use and gather data for a proposed reason.
- Testing Predictions: Ideas guess what will happen in experiments or observations. By checking these guesses carefully, scientists can see if the seen results match up with what was predicted in each hypothesis.
- Analysis and Interpretation of Data: Hypotheses give us a way to study and make sense of information. Researchers look at what they found and see if it matches the guesses made in their theories. They decide if the proof backs up or disagrees with these suggested reasons why things are happening as expected.
- Encouraging Objectivity: Hypotheses help make things fair by making sure scientists use facts and information to either agree or disagree with their suggested reasons. They lessen personal preferences by needing proof from experience.
- Iterative Process: People either agree or disagree with guesses, but they still help the ongoing process of science. Findings from testing ideas make us ask new questions, improve those ideas and do more tests. It keeps going on in the work of science to keep learning things.
People Also View:
Mathematics Maths Formulas Branches of Mathematics
Hypothesis is a testable statement serving as an initial explanation for phenomena, based on observations, theories, or existing knowledge . It acts as a guiding light for scientific research, proposing potential relationships between variables that can be empirically tested through experiments and observations.
The hypothesis must be specific, testable, falsifiable, and grounded in prior research or observation, laying out a predictive, if-then scenario that details a cause-and-effect relationship. It originates from various sources including existing theories, observations, previous research, and even personal curiosity, leading to different types, such as simple, complex, directional, non-directional, null, and alternative hypotheses, each serving distinct roles in research methodology .
The hypothesis not only guides the research process by shaping objectives and designing experiments but also facilitates objective analysis and interpretation of data , ultimately driving scientific progress through a cycle of testing, validation, and refinement.
Hypothesis – FAQs
What is a hypothesis.
A guess is a possible explanation or forecast that can be checked by doing research and experiments.
What are Components of a Hypothesis?
The components of a Hypothesis are Independent Variable, Dependent Variable, Relationship between Variables, Directionality etc.
What makes a Good Hypothesis?
Testability, Falsifiability, Clarity and Precision, Relevance are some parameters that makes a Good Hypothesis
Can a Hypothesis be Proven True?
You cannot prove conclusively that most hypotheses are true because it’s generally impossible to examine all possible cases for exceptions that would disprove them.
How are Hypotheses Tested?
Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data
Can Hypotheses change during Research?
Yes, you can change or improve your ideas based on new information discovered during the research process.
What is the Role of a Hypothesis in Scientific Research?
Hypotheses are used to support scientific research and bring about advancements in knowledge.

Please Login to comment...
Similar reads.
- Geeks Premier League
- School Learning
- Geeks Premier League 2023
- Maths-Class-12
- How to Underline in Discord
- How to Block Someone on Discord
- How to Report Someone on Discord
- How to add Bots to Discord Servers
- GeeksforGeeks Practice - Leading Online Coding Platform
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
IMAGES
VIDEO
COMMENTS
Hypothesis. A statement that could be true, which might then be tested. Example: Sam has a hypothesis that "large dogs are better at catching tennis balls than small dogs". We can test that hypothesis by having hundreds of different sized dogs try to catch tennis balls.
Hypothesis testing is a tool for making statistical inferences about the population data. It is an analysis tool that tests assumptions and determines how likely something is within a given standard of accuracy. Hypothesis testing provides a way to verify whether the results of an experiment are valid. A null hypothesis and an alternative ...
Hypothesis Testing. A hypothesis test is a statistical inference method used to test the significance of a proposed (hypothesized) relation between population statistics (parameters) and their corresponding sample estimators. In other words, hypothesis tests are used to determine if there is enough evidence in a sample to prove a hypothesis ...
A hypothesis is a proposition that is consistent with known data, but has been neither verified nor shown to be false. In statistics, a hypothesis (sometimes called a statistical hypothesis) refers to a statement on which hypothesis testing will be based. Particularly important statistical hypotheses include the null hypothesis and alternative hypothesis. In symbolic logic, a hypothesis is the ...
In hypothesis testing, the goal is to see if there is sufficient statistical evidence to reject a presumed null hypothesis in favor of a conjectured alternative hypothesis.The null hypothesis is usually denoted \(H_0\) while the alternative hypothesis is usually denoted \(H_1\). An hypothesis test is a statistical decision; the conclusion will either be to reject the null hypothesis in favor ...
Step 3: Collect Data and Compute Sample Statistics. After collecting the data, we find the sample mean. Now we can compare the sample mean with the null hypothesis by computing a z-score that describes where the sample mean is located relative to the hypothesized population mean. We use the z-score formula. Step 4: Make a Decision.
Types of Hypothesis. The hypothesis can be broadly classified into different types. They are: Simple Hypothesis. A simple hypothesis is a hypothesis that there exists a relationship between two variables. One is called a dependent variable, and the other is called an independent variable. Complex Hypothesis.
CIE. Spanish Language & Literature. Past Papers. Other Subjects. Revision notes on 5.1.1 Hypothesis Testing for the AQA A Level Maths: Statistics syllabus, written by the Maths experts at Save My Exams.
The null hypothesis is that there is no change in fatality rate, while the alternative hypothesis is that the fatality rate has decreased. A hypothesis test is performed on data collected for 24 months before and 24 months after the feature is built. Again, the p-value was 0.02.
Hypothesis tests are based on two hypotheses. The null hypothesis, H_ {0}, is a statement about the value of a population parameter (a parameter of the distribution of a random variable) which our data will tell us whether or not to reject. The alternate hypothesis, H_ {1}, is what we believe the parameter is if we reject the null hypothesis.
Thus the hypothesis is what we must assume in order to be positive that the conclusion will hold. Whenever you are asked to state a theorem, be sure to include the hypothesis. In order to know when you may apply the theorem, you need to know what constraints you have. So in the example above, if we know that a function is differentiable, we may ...
A hypothesis is a claim or statement that makes sense in the context of some information or data at hand but hasn't been established as true or false through experimentation or proof. In mathematics, any statement or equation that describes some relationship between certain variables can be termed as hypothesis if it is consistent with some ...
hypothesis. In mathematics, a hypothesis is an unproven statement which is supported by all the available data and by many weaker results. An unproven mathematical statement is usually called a " conjecture ", and while experimentation can sometimes produce millions of examples to support a conjecture, usually nothing short of a proof can ...
Hypothesis testing is the use of statistics to determine the probability that a given hypothesis is true. The usual process of hypothesis testing consists of four steps. 1. Formulate the null hypothesis H_0 (commonly, that the observations are the result of pure chance) and the alternative hypothesis H_a (commonly, that the observations show a real effect combined with a component of chance ...
A hypothesis (plural hypotheses) is a proposed explanation for an observation. The definition depends on the subject. In science, a hypothesis is part of the scientific method. It is a prediction or explanation that is tested by an experiment. Observations and experiments may disprove a scientific hypothesis, but can never entirely prove one.
Hypothesis test. A significance test, also referred to as a statistical hypothesis test, is a method of statistical inference in which observed data is compared to a claim (referred to as a hypothesis) in order to assess the truth of the claim. For example, one might wonder whether age affects the number of apples a person can eat, and may use a significance test to determine whether there is ...
If you're seeing this message, it means we're having trouble loading external resources on our website. If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
The null hypothesis is a hypothesis in which the sample observation results from chance. Learn the definition, principles, and types of the null hypothesis at BYJU'S. ... In mathematics, Statistics deals with the study of research and surveys on the numerical data. For taking surveys, we have to define the hypothesis. Generally, there are two ...
Review. In a hypothesis test, sample data is evaluated in order to arrive at a decision about some type of claim.If certain conditions about the sample are satisfied, then the claim can be evaluated for a population. In a hypothesis test, we: Evaluate the null hypothesis, typically denoted with \(H_{0}\).The null is not rejected unless the hypothesis test shows otherwise.
There are 5 main steps in hypothesis testing: State your research hypothesis as a null hypothesis and alternate hypothesis (H o) and (H a or H 1). Collect data in a way designed to test the hypothesis. Perform an appropriate statistical test. Decide whether to reject or fail to reject your null hypothesis. Present the findings in your results ...
Step 4: Your sample score of 27 needs to be converted into a Z value. To calculate Z = (27-19)/4= 2 (check the if you need to review how to do this process) Step 5: A 'Z' score of 2 is more extreme than the cut off Z of +1.96 (see figure above). The result is significant and, thus, the null hypothesis is rejected. You can find more examples ...
Hypothesis is a hypothesis is fundamental concept in the world of research and statistics. It is a testable statement that explains what is happening or observed. It proposes the relation between the various participating variables. Hypothesis is also called Theory, Thesis, Guess, Assumption, or Suggestion. Hypothesis creates a structure that ...